AArch64.cloud
..Benchmark tests for ARM-based AWS Graviton, Google Axion and Azure Cobalt CPUs
 Azure Cobalt 100 and Google Axion - image: Microsoft & Google
Azure Cobalt 100 and Google Axion - image: Microsoft & Google
So, it happened about a month ago. Azure came up with their latest Arm-based ‘Cobalt-100’ processor. After AWS and GCP, Microsoft is also competing in this new frontier of purpose-built efficient cloud computing. And, I wanted to run a benchmark test on these custom silicon. I tried with ‘Geekbench 6’ to compare all these CPUs. However, as it was not available as a command line tool on aarch64 platform, I decided to write a benchmarking library.
Arm-based chips from hyperscale cloud providers:
| Maker | Generation | Microarchitecture | vCPU | year |
|---|---|---|---|---|
| AWS | Graviton2 | Neoverse N1 | 64 | 2020 |
| Axion | Neoverse V2 | 72 | 2024 | |
| Microsoft | Azure Cobalt 100 | Neoverse N2 | 96 | 2024 |
Major cloud players had their purpose-built server and data centre for quite some time. But the performance competition at hyperscale providers has recently observed a new front- Arm based custom silicon. These CPUs are not only power efficient, but purpose-built for modern scaleout workloads – claimed to be 60% more efficient than their x86 counterparts. So, I was curious to see how these custom Arm-based CPUs perform under different workloads.
 Arm-based AWS Graviton family by Annapurna Labs.
Arm-based AWS Graviton family by Annapurna Labs.
This benchmark test is designed specifically for the Arm-based CPUs. These tests were run on cloud instances which are of similar price range($0.18-$0.20 per hour) irrespective of their total vCPU or core count.
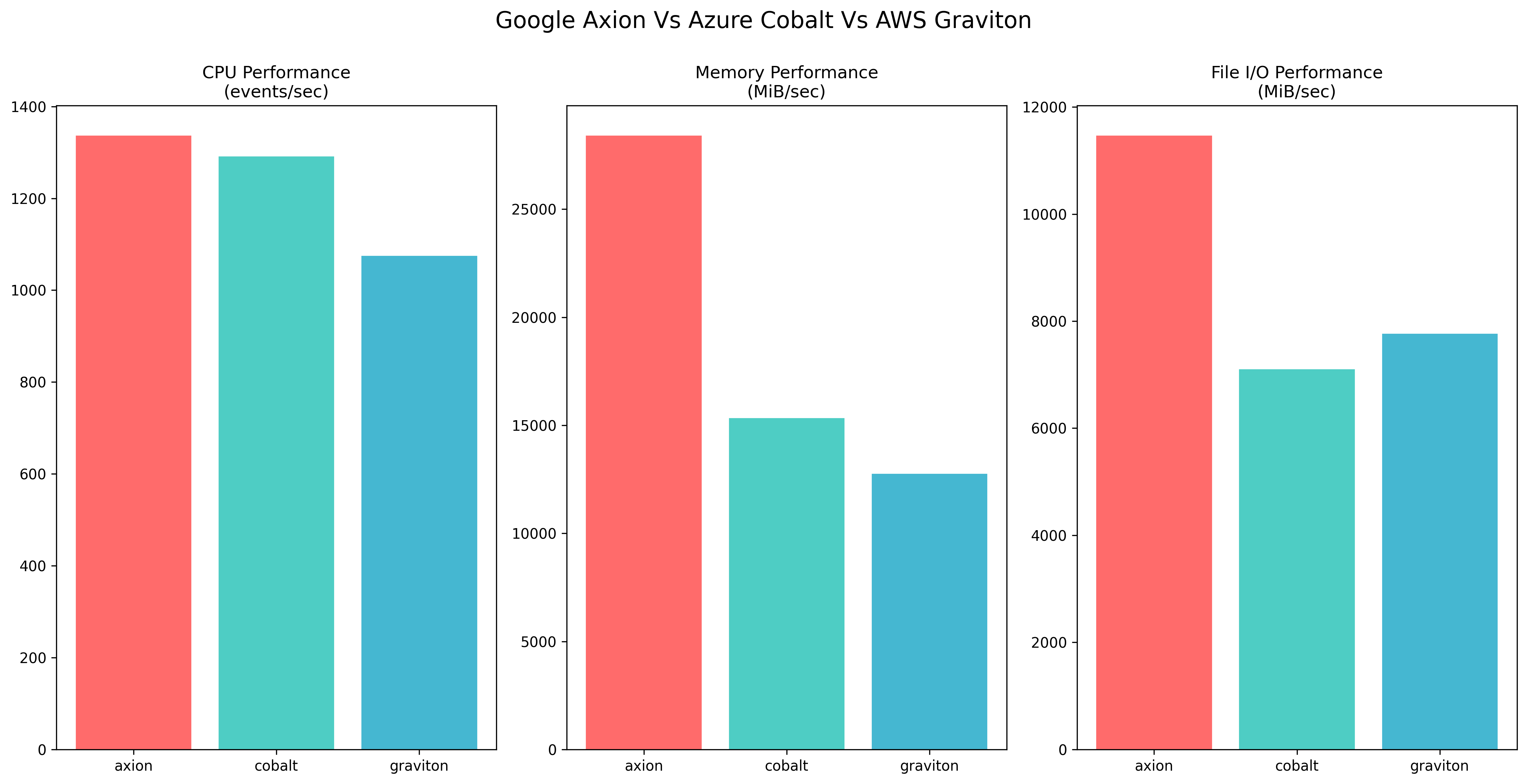 sysbench tests for ARM-based CPU: CPU, memory & I/O performance
sysbench tests for ARM-based CPU: CPU, memory & I/O performance
Though Arm-based cloud servers are now available on AWS, GCP and Azure, the first company to provide production grade Arm-based cloud servers was none of these hyperscalers. If my memory serves me right, back in 2018, an European cloud provider ‘Scaleway’ offered Arm based cloud instances. I was already using their some other product. So, I was curious on these new cloud offerings. What I have found back then was that the software eco-system around Arm-based cloud servers was no where near ‘mature’. It was almost impossible to find even popular web application packages available for aarch64 platform. So my earlier venture into Arm-based cloud servers was not fruitful.
Here, I have arranged a benchmark test for Google Axion, Microsoft Azure Cobalt, and AWS Graviton series processors.
I have run two separate benchmark tests:
- Sysbench tests for CPU, Memory, I/O
- LLM inferencing(token/second) benchmark test for CPU
While the sysbench tests were run using the sysbench library, for token/second benchmark, I have used my LLM inferencing benchmark library.
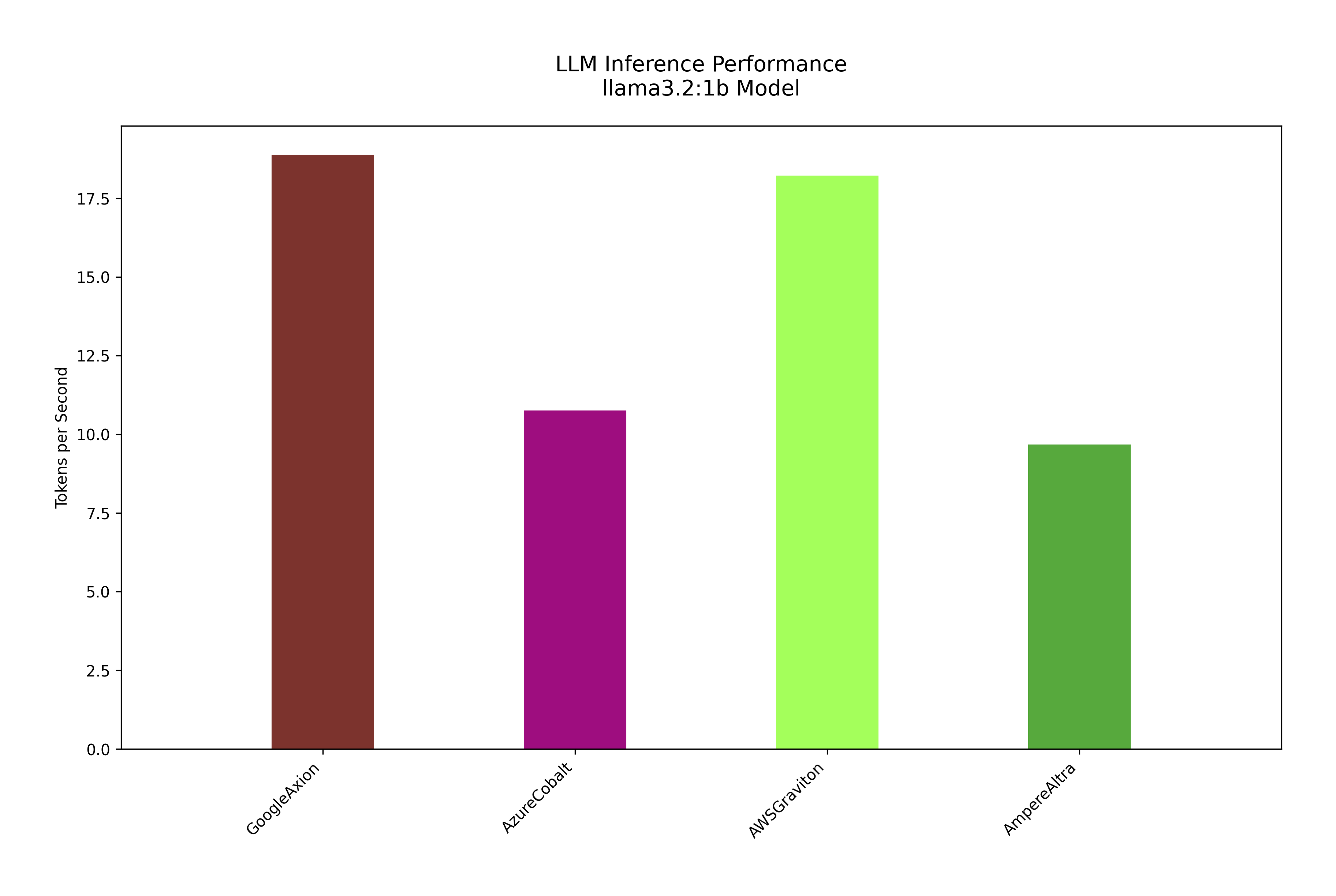 Token/second benchmark for ARM based AWS Graviton, Google Axion, Azure Cobalt 100 and Ampere Altra CPUs using Llama3.2:1b model
Token/second benchmark for ARM based AWS Graviton, Google Axion, Azure Cobalt 100 and Ampere Altra CPUs using Llama3.2:1b model
These tests were run on different Arm-based CPUs developed by AWS, Azure and GCP. While the Ampere Altra CPUs are currently available on multiple cloud providers like OCI, Scaleway and hetzner. The later tests compare these benchmark with the latest generation x86 CPUs from Intel and AMD. Both the latest Intel Emerald and AMD Genoa closely contested on LLM inferencing benchmark with their ARM-based counterparts. Google Axion had slight edge over AWS Graviton on both llama3.1:8b and llama3.2:1b token/second benchmarking.
| Chips | instance | vCPU/RAM |
|---|---|---|
| Amazon Graviton | c6g.2xlarge | 8/16 |
| Google Axion | c4a-highcpu-8 | 8/16 |
| Azure Cobalt | D4ps v6 | 4/16 |
| Ampere Altra | t2a-standard-4 | 4/16 |
| Emerald Rapids | n4-standard-4 | 4/16 |
| AMD Genoa | t2a-standard-4 | 4/16 |
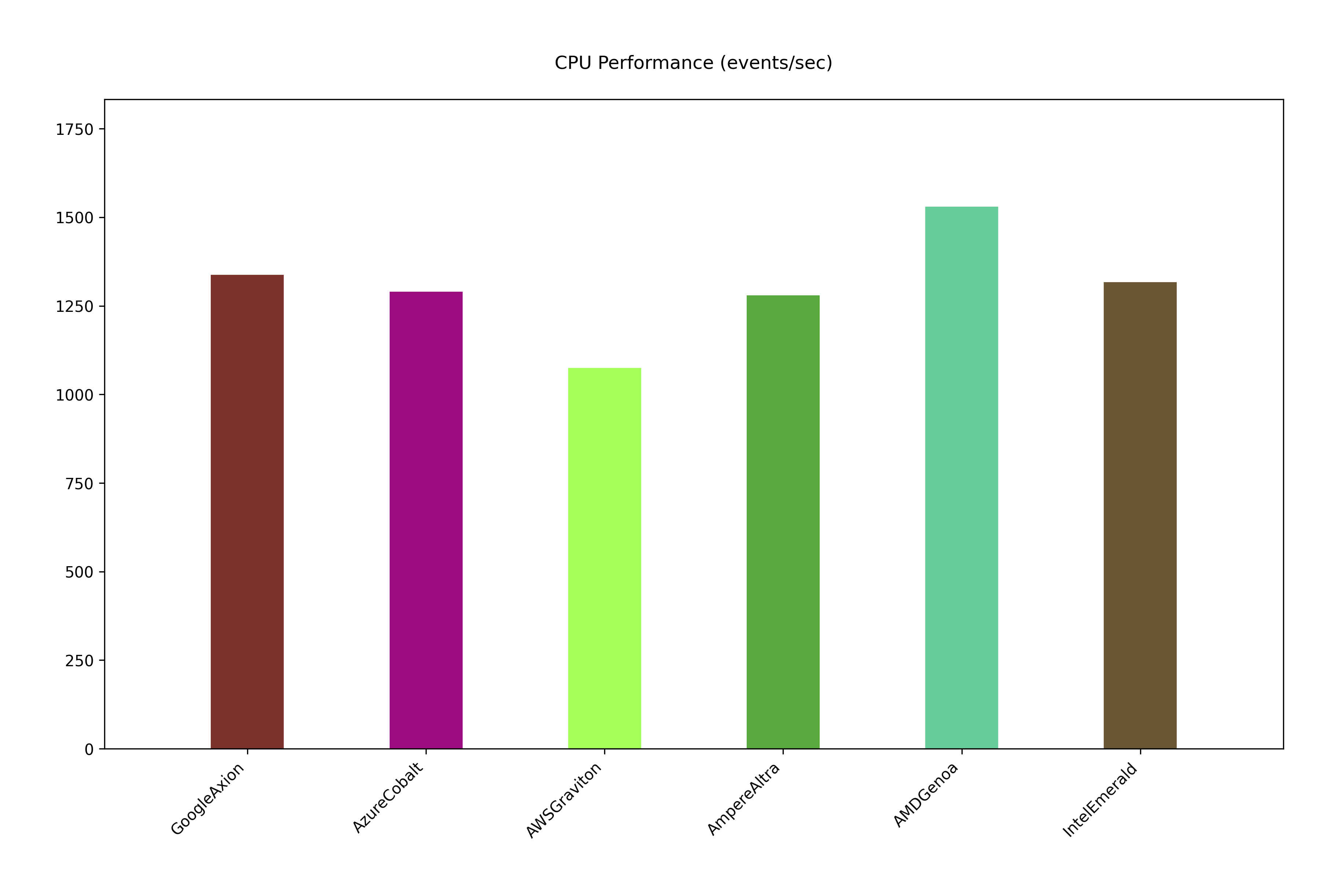 sysbench tests for ARM-based & x86 CPUs: CPU performance
sysbench tests for ARM-based & x86 CPUs: CPU performance
Now let’s run the LLM inference test on cross-platform CPUs:
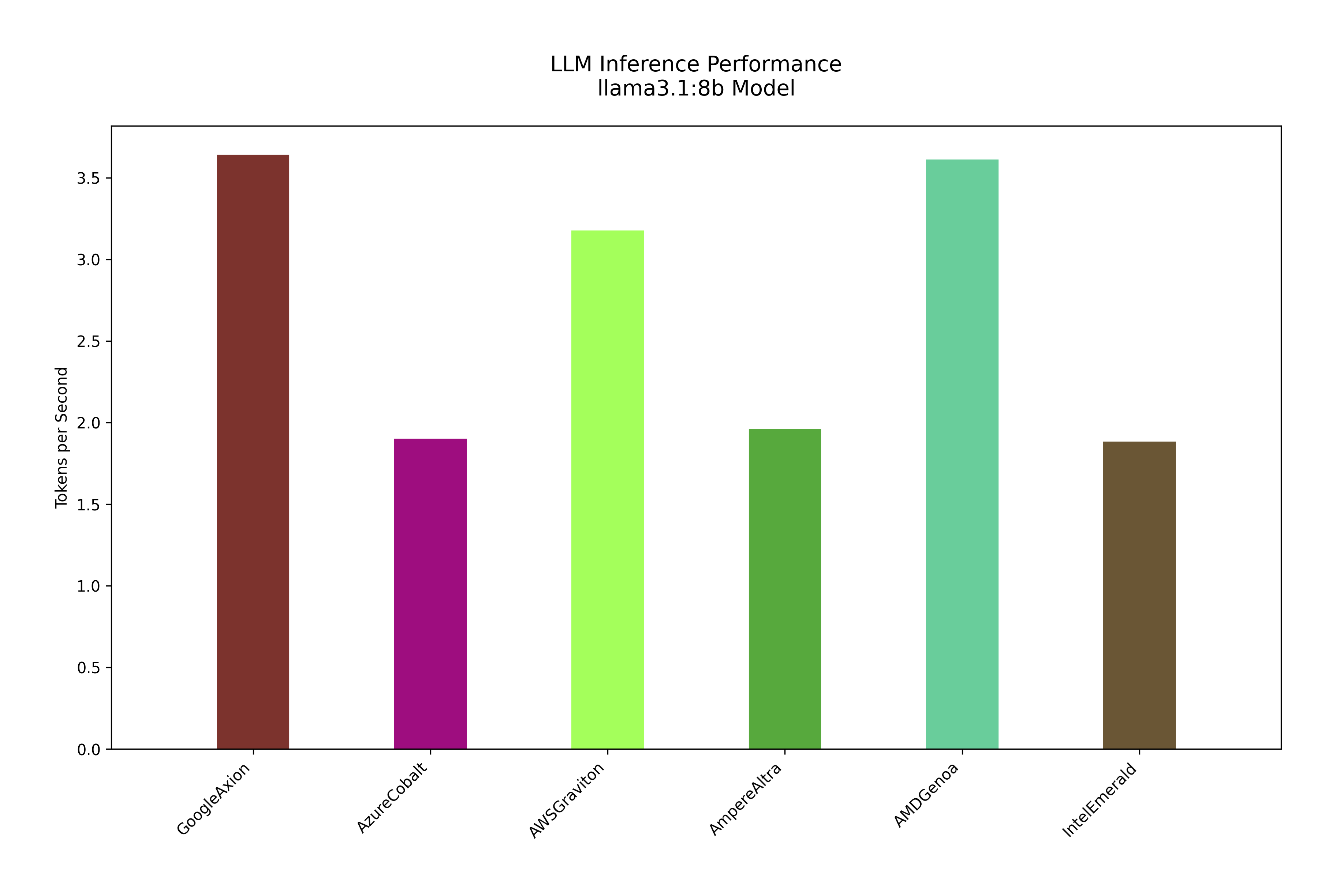 Token/second benchmark test for ARM-based and x86 CPUs using llama3.1:8b model
Token/second benchmark test for ARM-based and x86 CPUs using llama3.1:8b model
These tests were performed mostly on compute instances of a similar price(per hour) range. These tests are not representing the entire CPUs. My account quota(i.e. vCPU/region) on different cloud providers were a bottleneck on these tests. Though, these tests are supposed to be representative of the respective CPUs, running these tests on bare metal CPUs would be more reliable.
The code repository for this benchmark test can be found here:
https://github.com/ikthyandr/LLM-inference-as-a-CPU-Benchmark.